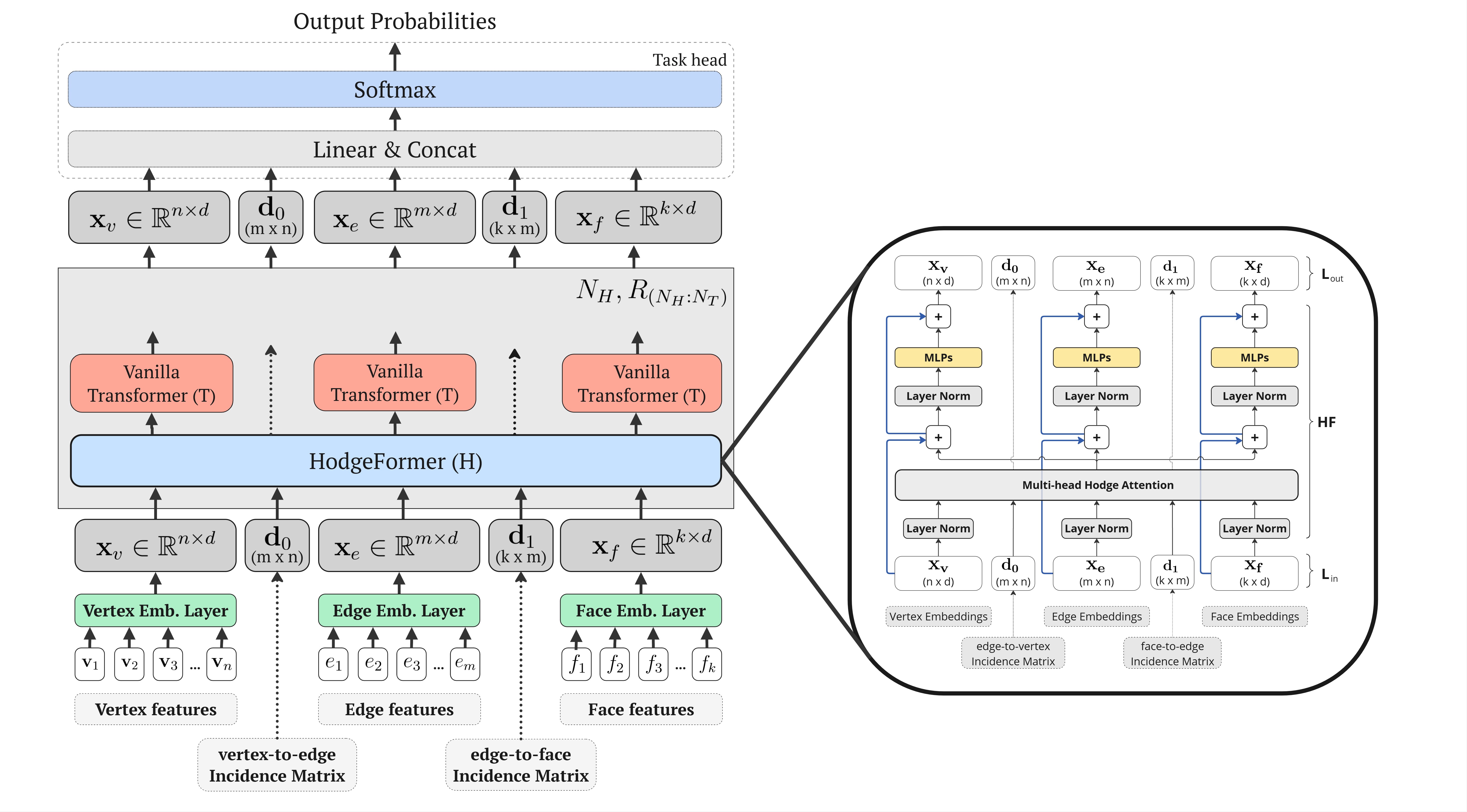
Currently, prominent Transformer architectures applied on graphs and meshes for shape analysis tasks employ traditional attention layers that heavily utilize spectral features requiring costly eigenvalue decomposition-based methods. To encode the mesh structure, these methods derive positional embeddings, that heavily rely on eigenvalue decomposition based operations, e.g. on the Laplacian matrix, or on heat-kernel signatures, which are then concatenated to the input features. This paper proposes a novel approach inspired by the explicit construction of the Hodge Laplacian operator in Discrete Exterior Calculus as a product of discrete Hodge operators and exterior derivatives, i.e. \((L:=\star_{0}^{-1} d_{0}^{T} \star_{1} d_{0})\). We adjust the Transformer architecture in a novel deep learning layer that utilizes the multi-head attention mechanism to approximate Hodge matrices \(\star_{0}\), \(\star_{1}\) and \(\star_{2}\) and learn families of discrete operators \(L\) that act on mesh vertices, edges and faces. Our approach results in a computationally-efficient architecture that achieves comparable performance in mesh segmentation and classification tasks, through a direct learning framework, while eliminating the need for costly eigenvalue decomposition operations or complex preprocessing operations.
Existing methods for 3D mesh analysis using spectral features rely on costly eigendecomposition of Laplacian matrices, creating a computational bottleneck and exhibiting high complexity. Alternatives convolutional based methods are often constrained by architectural limitations: some require specific mesh connectivity to construct their operators or use fixed operators that cannot adapt to the underlying data. On the other hand, modern Transformer-based approaches like MeT [9] still depend on pre-computed spectral features for positional encoding. This reliance on expensive, rigid, and often complex preprocessing steps limits the efficiency, scalability, and flexibility of deep learning on meshes.
The foundational work of HodgeNet by Smirnov and Solomon [4] demonstrated the effectiveness of applying Laplacian operators from Discrete Exterior Calculus (DEC) to triangular 3D meshes. In their approach, input features are used to learn diagonal Hodge Star operators, which then construct Laplacian operators applied to the features in a spectral learning framework.
Most common constructions of discrete Hodge Star operators are limited to diagonal matrices, representing only some specific Hodge operator realizations. The Galerkin method, widely used in Finite Element Methods (FEM) literature, prescribes systematic ways to discretize various differential operators, including the Hodge operator. The key idea is to project onto carefully designed basis functions (e.g., piecewise linear or higher order elements) and account for the overlap of these basis functions. These overlaps are used to design the mass matrix, which acts as a discrete Hodge operator. Unlike the diagonal Hodge operator, which considers only self-contributions, the Galerkin Hodge operator incorporates contributions from neighboring elements, resulting in a sparse, non-diagonal matrix.
The projection with matrices \(W_Q\), \(W_K\), \(W_V\) onto a learned space corresponds to a basis projection as in the Galerkin method, and the self-attention mechanism \(Q \cdot K^T\) encodes pairwise interactions and accounts for overlaps of the basis functions. If the self-attention mechanism is localized, then it aligns with Galerkin-style discretizations [20].
This paper introduces a novel Transformer architecture that leverages the explicit construction of Laplacian operators from Discrete Exterior Calculus (DEC) on triangular 3D meshes, drawing connections between discrete Hodge Star operators and Transformer-style attention mechanisms through Galerkin-inspired discretizations. The proposed architecture includes a novel Transformer-inspired layer that enables information propagation directly on the manifold through attention-based learnable Hodge Star matrices and incidence matrices, which serve as discrete exterior derivatives. By incorporating the structure considerations into the architecture, we do not rely at all on eigen-decomposition based methods, spectral features, or preprocessing steps, while achieving competitive performance compared to state-of-the-art approaches on meshes.
Performance of different methods on mesh classification and mesh segmentation tasks. Mesh classification is evaluated on the 30-class SHREC11 dataset evaluated on splits of 10 samples per class (split-10) and the Cube Engraving dataset. HodgeFormer achieves results comparable to the state-of-the-art without spectral features, eigenvalue decomposition operations or complex complementary structures. We report their base architecture, the mesh elements they operate on (v: vertices, e: edges, f: faces) and whether they depend on eigen-decomposition methods. The abbreviation "trns" denotes the transformer architecture.
| Method | Type | Acts On | Eigen Decomp. | SHREC11 (split-10) | Cube Engrav. | Human Simplified | COSEG Vases | COSEG Chairs | COSEG Aliens |
|---|---|---|---|---|---|---|---|---|---|
| HodgeNet [4] | mlp | v | Yes | 94.7% | n/a | 85.0% | 90.3% | 95.7% | 96.0% |
| DiffusionNet [5] | mlp | v | Yes | 99.5% | n/a | 90.8% | n/a | n/a | n/a |
| LaplacianNet [6] | mlp | v | Yes | n/a | n/a | n/a | 92.2% | 94.2% | 93.9% |
| Laplacian2Mesh [7] | cnn | v | Yes | 100.0% | 91.5% | 88.6% | 94.6% | 96.6% | 95.0% |
| MeT [9] | tms | f | Yes | n/a | n/a | n/a | 99.8% | 98.9% | 99.3% |
| MeshCNN [1] | cnn | e | No | 91.0% | 92.2% | 85.4% | 92.4% | 93.0% | 96.3% |
| PD-MeshNet [2] | cnn | ef | No | 99.1% | 94.4% | 85.6% | 95.4% | 97.2% | 98.2% |
| MeshWalker [3] | rnn | v | No | 97.1% | 98.6% | n/a | 99.6% | 98.7% | 99.1% |
| SubDivNet [8] | cnn | f | No | 99.5% | 98.9% | 91.7% | 96.7% | 96.7% | 97.3% |
| HodgeFormer (ours) | tms | vef | No | 98.7% | 95.3% | 90.3% | 94.3% | 98.8% | 98.3% |
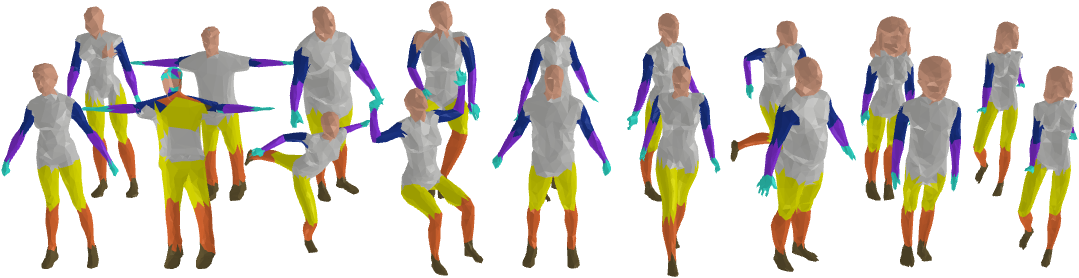
HodgeFormer demonstrates strong robustness to common mesh corruptions, showing minimal performance degradation when subjected to various types of noise and simplification.
Performance degradation on Human dataset:

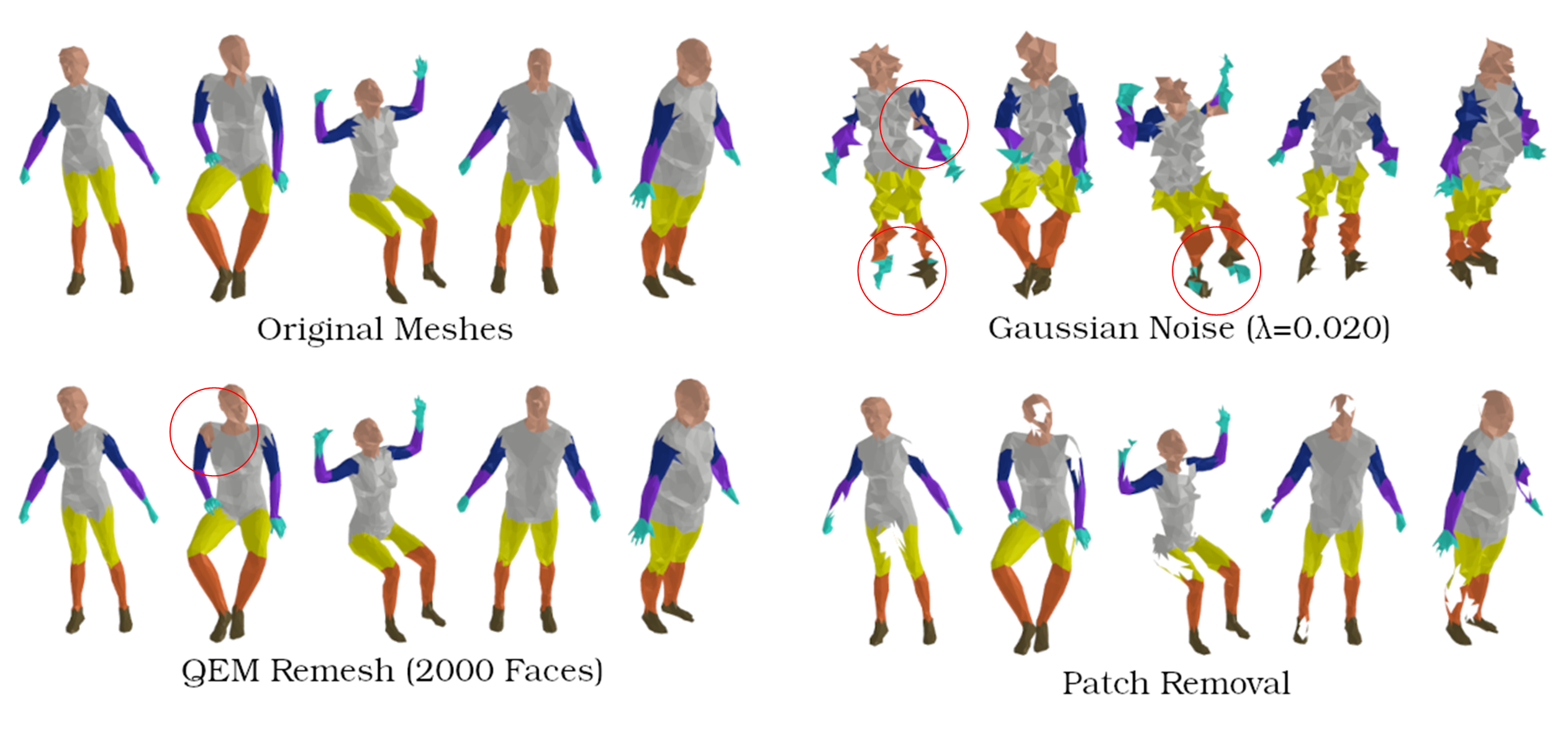
@article{nousias2025hodgeformer,
author = {Nousias, Akis and Nousias, Stavros},
title = {HodgeFormer: Transformers for Learnable Operators on Triangular Meshes through Data-Driven Hodge Matrices},
journal = {arXiv preprint},
year = {2025}
}